
 English
English
Zadanie DNA (dna)
DNA
Memory limit: 128 MB
The mad scientist Byteasar would like to give birth to a new kind of creatures. For this, he has decided to modify the genome of a Bytean mouse.
A DNA can be described as a sequence nucleotides denoted by
letters A, C, G and T.
Byteasar's master plan is quite simple:
using the DNA of a mouse, he is going to create a new DNA of the same length
that is as little similar to the mouse's DNA as possible.
The similarity of two DNAs is the length of their longest common subsequence.
The longest common subsequence of two words  ,
, 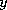 is defined as the longest word
that can be obtained from each of
is defined as the longest word
that can be obtained from each of  ,
, 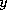 by removing some (possibly none) letters from both words.
(Note that two words may have several longest common subsequences.
For example, the longest common subsequences of the words CACCA and CAAC
are: CAA and CAC.)
Write a program that computes the requested DNA.
by removing some (possibly none) letters from both words.
(Note that two words may have several longest common subsequences.
For example, the longest common subsequences of the words CACCA and CAAC
are: CAA and CAC.)
Write a program that computes the requested DNA.
Input
The first line of input contains one integer  (
(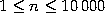 ), the length
of the DNA of a Bytean mouse.
The second line contains a description of nucleotides in the DNA: a sequence of
), the length
of the DNA of a Bytean mouse.
The second line contains a description of nucleotides in the DNA: a sequence of
 uppercase letters A, C, G, T.
uppercase letters A, C, G, T.
Output
The first line of output should contain one integer: the similarity of the Bytean mouse's DNA
and the DNA computed by your program.
The second line should hold a sequence of  letters A, C, G, T.
This should be a DNA that is as little similar to the DNA from the input as possible.
Should there be many correct answers, your program may output any one of them.
letters A, C, G, T.
This should be a DNA that is as little similar to the DNA from the input as possible.
Should there be many correct answers, your program may output any one of them.
Example
For the input data:
4 GACT
one of the correct results is:
1 TCAG
Task author: Jakub Lacki.